SQL2000作为企业数据库管理工具,它配备了常用的工具,做到了傻瓜式的集中统一。
集中注意力在业务逻辑,而不需要为了零散分离的工具而费尽心力。可视化操作降低了维护的专业性,将部分日常维护工作转给了客户方的普通管理员。维护工作,这是一个很大的技术门槛和成本因素。
一。 启动

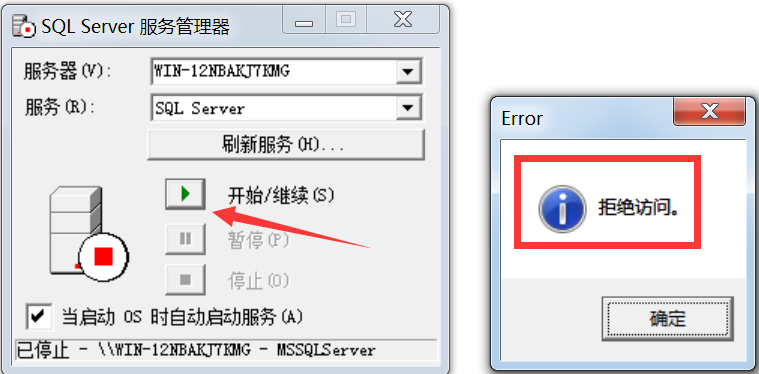
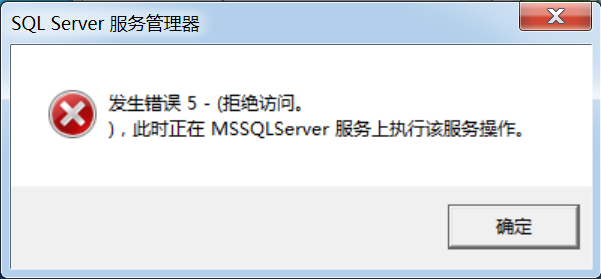
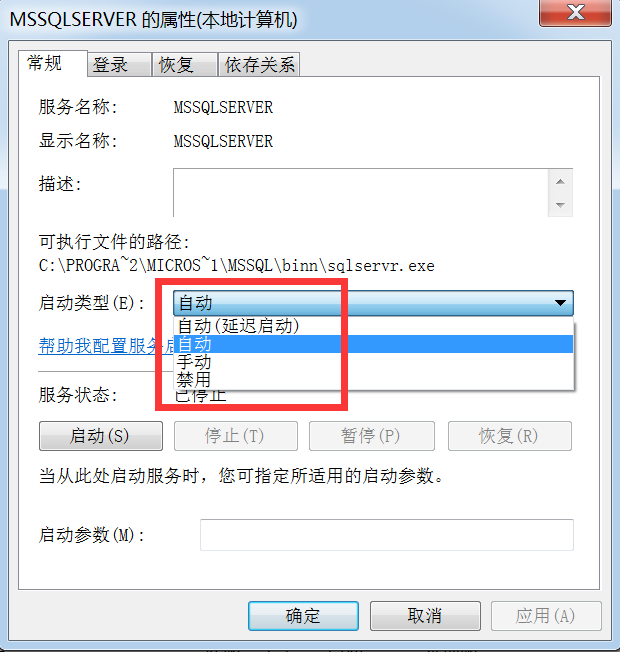
有可能出现这个错误,原因是:控制面板\所有控制面板项\用户帐户-》更改用户账户控制设置
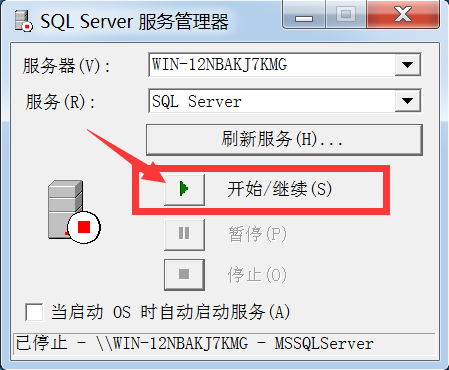
除了在这个地方能启动外,在控制面板\所有控制面板项\管理工具\服务,找到
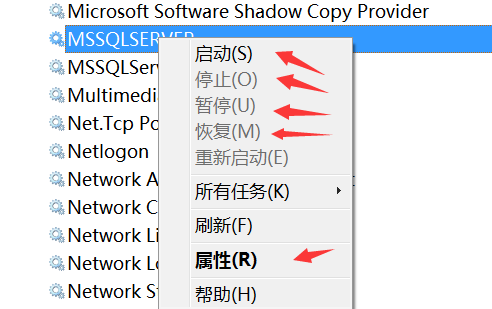
可以点右键,直接启动或者停止。也可以在属性里面具体修改,比如改为手动启动或者禁用。这样当我们开发完一个项目后,暂时不需要时,就可以不开机启动。特别是当你安装了好几个数据库系统时,这点尤为重要。
二。主要的管理工具

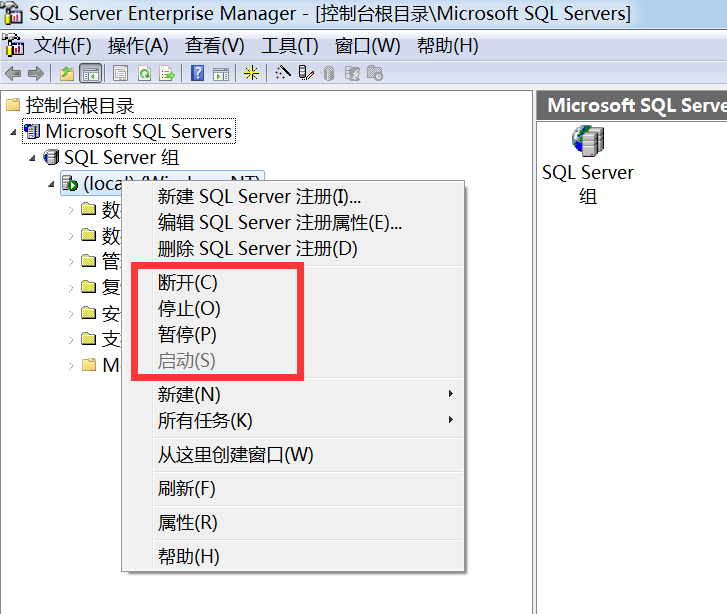
在这里也是可以启停数据库的。不过这只是它的其中一个最小的用途。
我们用到的主要是这三个方面
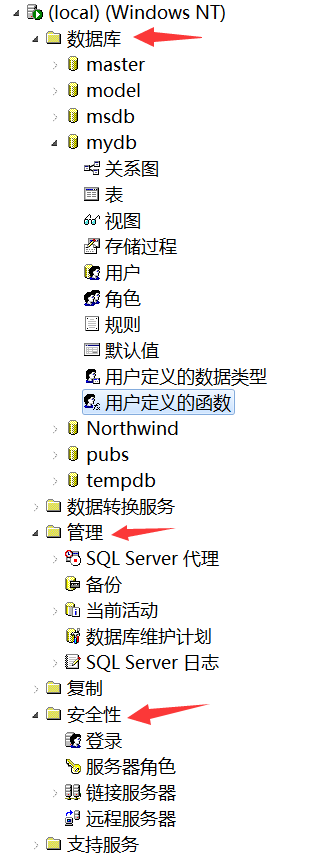
2.1 创建数据库
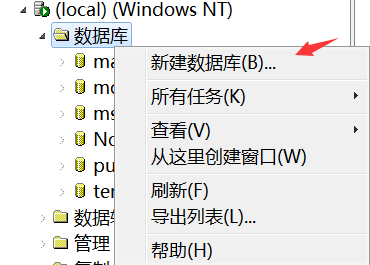
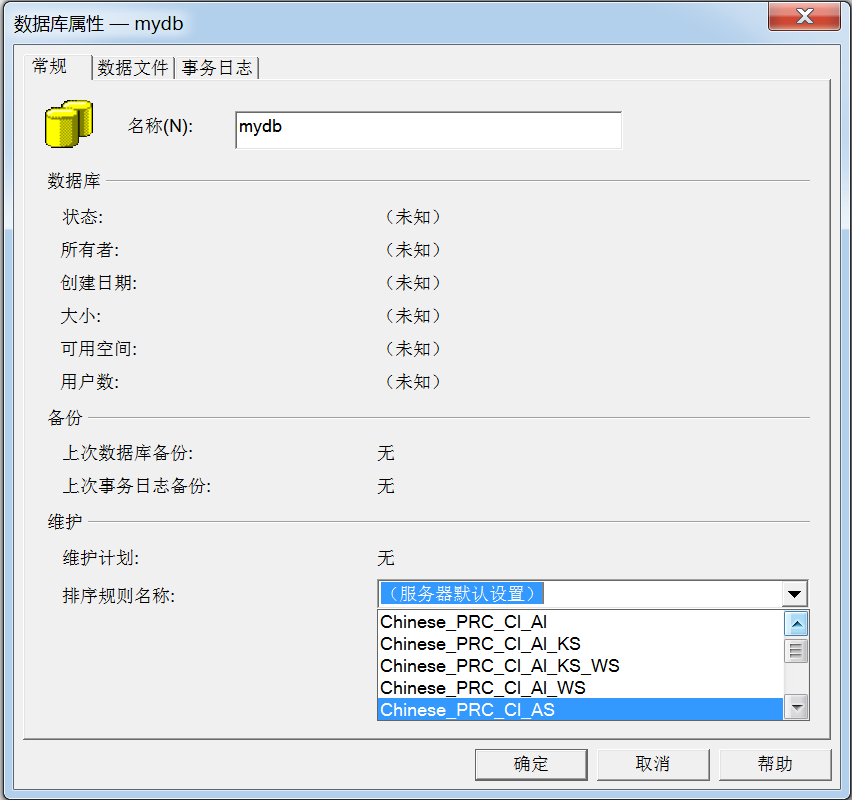
关于排序,当栏位中有char,varchar时,需要在语句的where条件中的栏位的排序规则是一样的。
如果不一样,需要特殊指定,这个我们在SQL语法部分将会特别讲到。
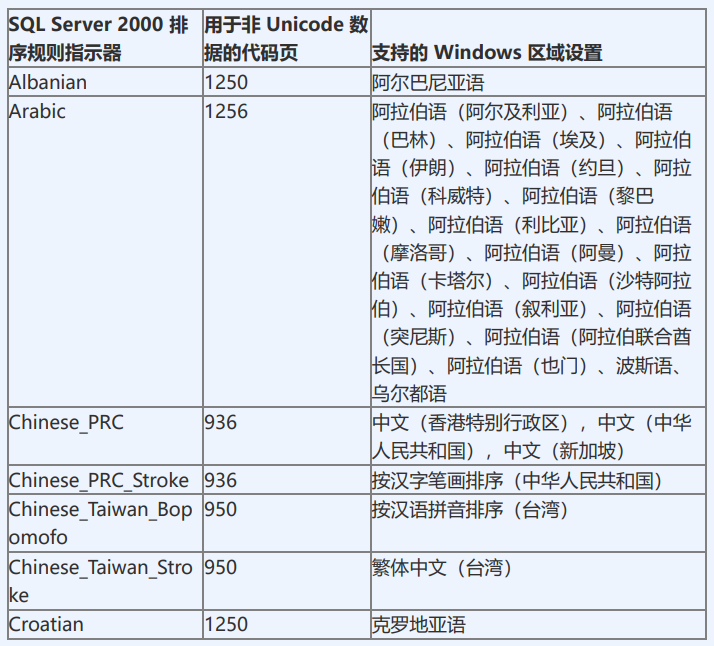
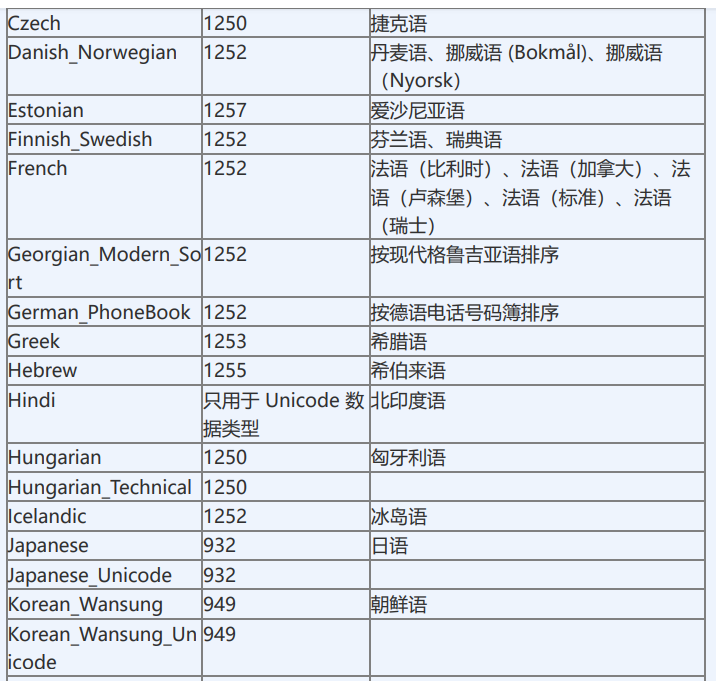
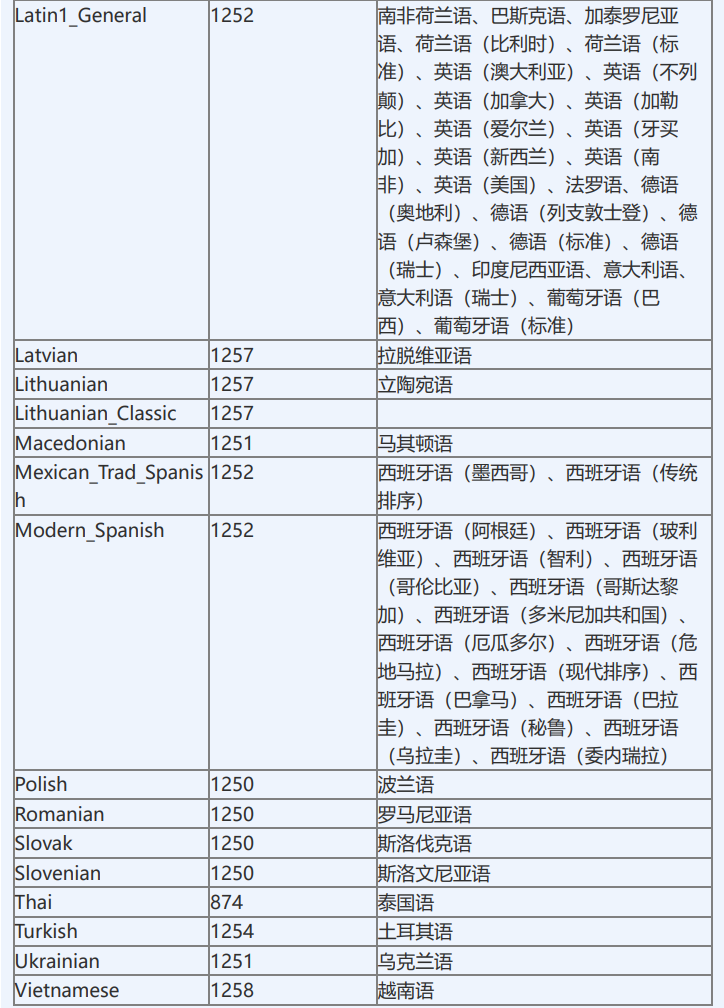
有专门针对国外客户的系统会指定具体的语言的排序规则。
而我们指定汉语时,主要注意的是:
排序规则名称由两部份构成,前半部份是指本排序规则所支持的字符集。 如:
Chinese_PRC_CS_AI_WS 前半部份:指UNICODE字符集,Chinese_PRC_指针对大陆简体字UNICODE的排序规则,按拼音排序。 Chinese_PRC_Stroke 表示按汉字笔画排序; 排序规则的后半部份即后缀 含义:
_BIN 二进制排序
_CI(CS) 是否区分大小写,
CI不区分,
CS区分(case-insensitive/case-sensitive)
_AI(AS) 是否区分重音,AI不区分,AS区分(accent-insensitive/accent-sensitive)
_KI(KS) 是否区分假名类型,KI不区分,KS区分(kanatype-insensitive/kanatype-sensitive)
_WI(WS) 是否区分宽度 WI不区分,WS区分(width-insensitive/width-sensitive)
区分大小写:如果想让比较将大写字母和小写字母视为不等,请选择该选项。
区分重音:如果想让比较将重音和非重音字母视为不等,请选择该选项。如果选择该选项, 比较还将重音不同的字母视为不等。
区分假名:如果想让比较将片假名和平假名日语音节视为不等,请选择该选项。
区分宽度:如果想让比较将半角字符和全角字符视为不等,请选择该选项。
注意:当你安装时会指定排序规则。然后创建数据库时我们也是默认排序。我们创建的表就默认使用了这个规则(一般我们不会特别去选择这个。这一般情况下是没有任何问题的。
唯一的就是要联合其他的库中的表时,或者是从其他数据库导入一个表时,就会出现排序规则不同无法进行where条件的相等和order by。这时就要用语句指定某个栏位用什么排序。这个在SQL语法部分再讲。
当前我们要知道如果要同时使用两个表或者多个表的某个栏位,他们的排序规则需要一致。这个只针对文字串的类型。